深度学习目标检测:R-CNN, SSPNet, Fast R-CNN, Faster R-CNN, YOLO, SSD
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来。 或者是,图像中有那些目标,目标的位置在那。这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫。 就在图像找出来猫,狗的位置,并标注出来 是狗还是猫。
这就涉及到两个问题:
- 目标识别,识别出来目标是猫还是狗,Image Classification解决了图像的识别问题。
- 定位,找出来猫狗的位置。
本文将详细介绍目前深度学习目标检测算法的几种热门算法R-CNN, SSPNet, Fast R-CNN, Faster R-CNN, YOLO, SSD的比较
1. R-CNN
RCNN (论文:Rich feature hierarchies for accurate object detection and semantic segmentation) 是将CNN方法引入目标检测领域, 大大提高了目标检测效果,可以说改变了目标检测领域的主要研究思路, 紧随其后的系列文章:(RCNN),Fast RCNN, Faster RCNN 代表该领域当前最高水准。
【论文主要特点】(相对传统方法的改进)
-
速度: 经典的目标检测算法使用滑动窗法依次判断所有可能的区域。本文则(采用Selective Search方法)预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上(采用CNN)提取特征,进行判断。
-
训练集: 经典的目标检测算法在区域中提取人工设定的特征。本文则采用深度网络进行特征提取。使用两个数据库: 一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。 一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置,一万图像,20类。 本文使用识别库进行预训练得到CNN(有监督预训练),而后用检测库调优参数,最后在检测库上评测。
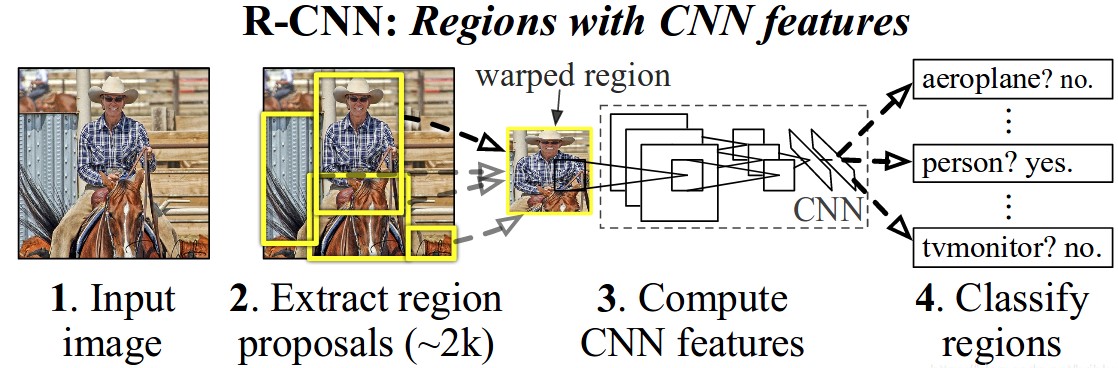
RCNN算法分为4个步骤:
- 候选区域生成: 一张图像生成1K~2K个候选区域(采用Selective Search 方法)
- 特征提取:对每个候选区域,使用深度卷积网络提取特征 (CNN)
- 类别判断:特征送入每一类的SVM 分类器,判别是否属于该类
- 位置精修:使用回归器精细修正候选框位置
下图给出了R-CNN过程
1.1
参考文献:
- 原文作者:jchen
- 原文链接:http://jchenTech.github.io/post/%E5%9B%BE%E5%83%8F%E5%A4%84%E7%90%86%E4%B8%8E%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8BR-CNN-SSPNet-Fast-R-CNN-Faster-R-CNN-YOLO-SSD/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。